Рассматриваемый алгоритм создан на основе метода прямого поиска, описанного в [1] как метод Хука-Дживса. Общая идеология этого метода состоит в чередовании поиска вокруг базовой точки, при котором происходит определение направления убывания функции, и поиска по образцу, при котором происходит корректируемое движение по направлению убывания.
В оригинальном методе Хука-Дживса, как при поиске вокруг базовой точки, так и при поиске вокруг образца, применен существенно последовательный алгоритм - координаты текущей точки для вычисления зависят от значения функции в предыдущей точке. Это не позволяет провести распараллеливание. Кроме того, алгоритм имеет некоторую анизотропию - предпочтительным является направление возрастания аргумента функции. При распараллеливании было разработано три варианта алгоритма поиска минимума функции многих переменных. Эти алгоритмы различаются глубиной перебора. Алгоритм 1 наиболее близок к оригинальному методу Хука-Дживса. Ввиду того, что на некоторых задачах метод Хука-Дживса дает неудовлетворительные результаты, были разработаны алгоритмы 2 и 3, отличающиеся большей степенью перебора. Применение последних алгоритмов повышает вероятность нахождения глобального минимума.
В алгоритме 1, как при поиске вокруг базовой точки, так и при поиске вокруг образца, применяется следующее правило - проверяются все точки, у которых только одна координата отличается от координат точки, вокруг которой происходит поиск на текущий шаг:
|
Таким образом, число точек при поиске вокруг точки x* в этом алгоритме - 2 × n, тогда как в методе Хука-Дживса число точек при поиске колеблется от n до 2 × n.
В алгоритме 2 при поиске вокруг образца без изменений используется алгоритм метода Хука-Дживса.
При поиске вокруг базовой точки в этом алгоритме перебирается большое количество точек:
|
Алгоритм 3 отличается от алгоритма 2 еще большим перебором при поиске вокруг базовой точки:
|
Число точек при поиске вокруг x* в этом алгоритме - 3n - 1.
Алгоритм прямого поиска, примененный для решения задачи поиска минимума, является последовательным по своей структуре. Но, несмотря на это, он поддается распараллеливанию на этапе поиска вокруг базовой точки.
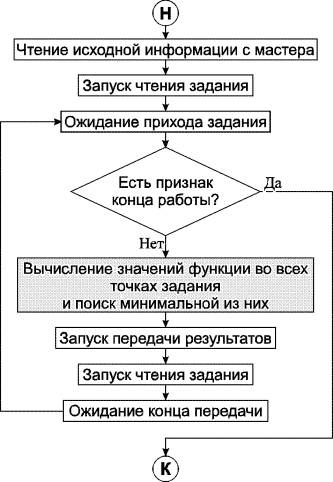
Распараллеливание ведется по схеме процессорной фермы. Задача-мастер реализует алгоритм поиска минимума функции, обращаясь, по необходимости, к задачам-рабочим для вычисления значений минимизируемой функции. Рабочий принимает задание от мастера, вычисляет значения функции в точках задания, находит их минимум и отправляет результат мастеру. Обобщенная блок-схема работы алгоритма задачи-рабочего показана на рис. 1.
На рис. 2 приведена обобщенная блок-схема задачи-мастера. Разъясним подробнее смысл некоторых пунктов алгоритма.
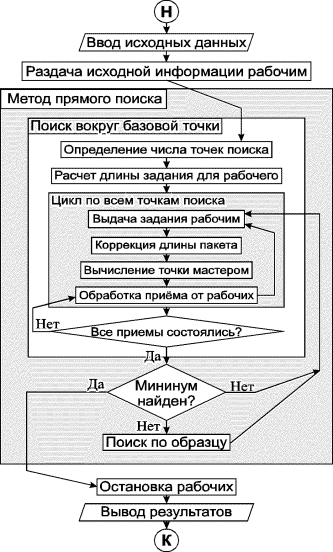
Расчет длины задания для рабочего. Длина задания - число точек, которые обрабатываются рабочим как единое целое, - вычисляется по формуле
|
Выдача задания рабочим. Если есть свободные рабочие и до конца поиска осталось точек не меньше чем Lpak, то на свободный рабочий посылается пакет с заданием. Таким образом, если Kp = 1, то мастер рассчитывает при одном поиске Lpak+ mod (k/NCPU) точек, где под mod(M/N) подразумевается остаток от целочисленного деления.
Коррекция длины пакета. Эффективная загрузка процессоров получается, когда исключаются ситуации, при которых один процессор работает, а остальные ожидают результатов; т.е. все процессоры должны, по возможности, завершить работу одновременно. Для достижения этого, с некоторого момента по мере приближения к концу поиска, первоначальная длина пакета уменьшается. Эффективный алгоритм такой коррекции находится в стадии разработки.
Вычисление точки мастером. На этом этапе происходит вычисление на главном процессоре одной из точек поиска. Значение функции в этой точке сравнивается с текущим минимумом и, при необходимости, обновляет его.
Под обработкой приема от рабочих подразумевается проверка завершенности приема результатов счета от рабочего. Если прием завершен, то принятая минимальная точка пакета сравнивается с текущим минимумом и, при необходимости, обновляет его.
В конце поиска может возникнуть ситуация, когда мастеру считать уже нечего, а от рабочих результаты еще не поступили. В этом случае реализуется цикл, соответствующий стрелке <<Нет>> от условного блока Все приемы состоялись?.
Минимум найден? Если итерации поиска необходимо продолжать, то в зависимости от результатов поиска вокруг базовой точки либо происходит переход к поиску по образцу, либо осуществляется новый цикл поиска вокруг базовой точки с уменьшенным значением h.
Приведем вид пакета с заданием, передаваемый от мастера к рабочему:
typedef struct to__worker
{
double yb[MAXN]; /* координаты базовой точки */
double h; /* шаг */
long n0; /* первый вычисляемый номер */
long n1; /* последний вычисляемый номер */
} TO_WORKER;
По координатам точки, вокруг которой происходит поиск, текущему шагу и номеру точки однозначно (для каждого алгоритма) определяются координаты тестируемой точки. Использование для идентификации точки одной переменной типа long накладывает ограничение на максимальную размерность задачи: n ё 31 для алгоритма 2 и n ё 19 для алгоритма 3. Отметим, что решение задач с размерностью, превышающей данные ограничения, будет занимать огромное время даже при использовании МВС-100. Пакет с результатом, передаваемый от рабочего к мастеру:
typedef struct to__master
{
long nmin; /* номер минимума */
double yr[MAXN+1]; /* координаты
минимума со значением функции */
}
TO_MASTER;
В этой структуре содержится избыточная информация - по номеру точки легко восстанавливаются координаты точки. Но при малом MAXN потери на передачу большего массива будут неощутимы. Следует отметить, что такая избыточность помогла обнаружить ошибку в одном из процессорных узлов.
В алгоритмах 2 и 3 алгоритм поиска вокруг образца остался таким же, как и в исходном методе Хука-Дживса. Поэтому распараллеливание поиска по образцу в этих алгоритмах признано нецелесообразным, так как число точек, вычисляемых при поиске вокруг образца, пренебрежимо мало по сравнению с числом точек, вычисляемых при поиске вокруг базовой точки.
В алгоритме 1 при поиске вокруг образца применен алгоритм поиска вокруг базовой точки. Этот алгоритм распараллелен. Для алгоритма 1, который допускает большую размерность задачи, неэффективность пакета TO_MASTER становится существенной. Ведутся работы по созданию более эффективного алгоритма и пакета для алгоритма 1.
На рис. 3-6 приведены графики времени счета для одной из постановок задачи о брахистохроне с трением [2, 3]. Графики, на которых по горизонтальной оси откладывается число процессоров, а по вертикальной оси - время, во многих случаях не обладают достаточной выразительностью даже при использовании логарифмических координат. Введем следующее понятие - относительное время TN*, вычисляемое по формуле
|
процессоре. Можно указать следующие свойства TN*:
- T1* ╨ 1,
- TN* Ё 1 (может нарушаться в отдельных случаях),
- при <<абсолютном>> распараллеливании TN* = 1.
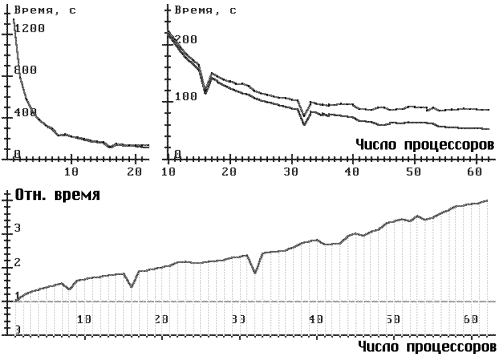
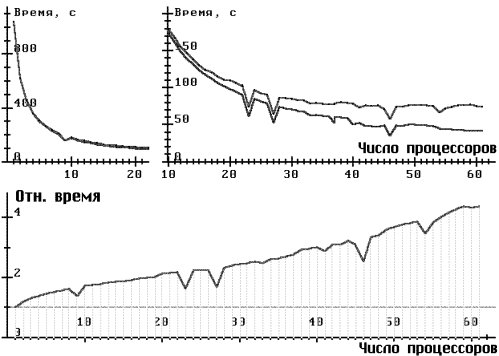
На рис. 3, 4, в верхней части помещены графики зависимости времени счета от числа процессоров (используется разный масштаб для разного числа процессоров). Верхние кривые - время брутто (от начала считывания исходных данных до конца вывода результатов), нижние кривые - время нетто (время << Метода прямого поиска>>, см. рис. 2). В отдельных случаях проводились неоднократные запуски при постоянном числе процессоров, этим значениям N соответствуют вертикальные участки графиков (особенно это заметно на рис. 4).
В нижней части рис. 3, 4, показано относительное время в зависимости от числа процессоров. Графики получены при усреднении значений времени брутто.
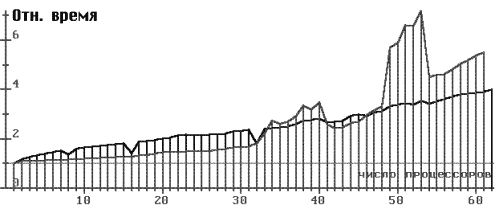
На рис. 3, 4 задача о брахистохроне сводилась к минимизации функции 19 переменных, применялся алгоритм 2. Для рис. 3 коэффициент Kp = 1 и видны характерные <<провалы>> при числе процессоров 8, 16, 32, т.е. когда число процессоров равно степени двойки. В этом случае число точек кратно числу процессоров, следовательно, mod(k/N) = 0. На рис. 4 (Kp = 3) разброс результатов для числа процессоров от 33 до 40 объясняется, видимо, попаданием задачи на разные вычислительные поля, содержащие процессоры разного быстродействия. Отсутствие такого эффекта для случая рис. 3 объясняется, возможно, тем, что при Kp = 1 срабатывает эффект торможения счета медленными процессорами.
На рис. 5 для сравнения приведено относительное время при Kp = 1 и Kp = 3. Видно, что для N ё 32 коэффициент Kp = 3 дает лучшую эффективность. При большем числе процессоров однозначно выбрать эффективное значение Kp на данном этапе исследований не уда└тся.
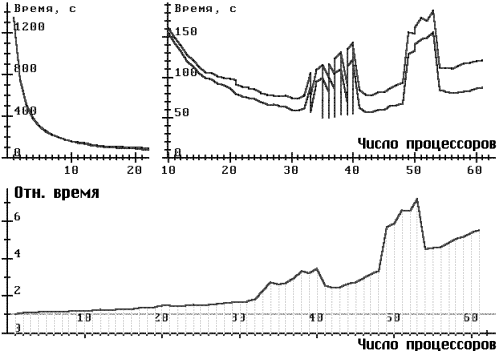
Для рис. 6 решение задачи о брахистохроне сводилось к минимизации функции 11 переменных, применялся более переборный алгоритм 3, Kp = 1. В этом случае легко объясняются провалы при числе процессоров 9, 23, 27 и 46 (9 = 32, 27 = 33, 311-1 = 2 ×23 ×3851).
- Разработка эффективного алгоритма коррекции длины пакета в конце поиска.
- Улучшение начальной части алгоритма, ответственной за раздачу исходной информации. При большом числе процессоров различие между временем брутто и временем нетто может составлять более трети всего времени счета (рис. 6).
- Реализация и отладка алгоритма 1, что позволит минимизировать функции большого числа переменных (более 1000).
- Для решения задач вариационного исчисления полезно создание программы, в которой начальный расчет проводится алгоритмом 2 или 3 при малой размерности оптимизируемой функции, затем уточняется алгоритмом 1 для функции большой размерности.
СПИСОК ЛИТЕРАТУРЫ